Debugging Docker Connection Reset by Peer
2020-05-03co-written with Dustin Mitchell and cross-posted here
Symptoms
At the end of January this year the Taskcluster team was alerted to networking issues in a user's tasks. The first
report involved ETIMEDOUT but later on it became clear that the more frequent issue was involving ECONNRESET in the middle of downloading artifacts necessary to
run the tests in the tasks. It seemed it was only occurring on downloads from Google (https://dl.google.com) on our workers running in GCP, and only with relatively large artifacts. This led
us to initially blame some bit of infrastructure outside of Taskcluster but eventually we found the issue to be with how Docker was handling networking on our worker machines.
Investigation
The initial stages of the investigation were focused on exploring possible causes of the error and on finding a way to reproduce the error.
Investigation of an intermittent error in a high-volume system like this is slow and difficult work. It's difficult to know if an intervention fixed the issue just because the error does not recur. And it's difficult to know if an intervention did not fix the issue, as "Connection reset by peer" can be due to transient network hiccups. It's also difficult to gather data from production systems as the quantity of data per failure is unmanageably high.
We explored a few possible causes of the issue, all of which turned out to be dead ends.
- Rate Limiting or Abuse Prevention - The TC team has seen cases where downloads from compute clouds were limited as a form of abuse prevention. Like many CI processes, the WPT jobs download Chrome on every run, and it's possible that a series of back-to-back tasks on the same worker could appear malicious to an abuse-prevention device.
- Outages of the download server - This was unlikely, given Google's operational standards, but worth exploring since the issues seemed limited to
dl.google.com. - Exhaustion of Cloud NAT addresses - Resource exhaustion in the compute cloud might have been related. This was easily ruled out with the observation that workers are not using Cloud NAT.
At the same time, several of us were working on reproducing the issue in more controlled circumstances. This began with interactive sessions on Taskcluster workers, and soon progressed to a script that reproduced the issue easily on a GCP instance running the VM image used to run workers. An important observation here was that the issue only reproduced inside of a docker container: downloads from the host worked just fine. This seemed to affect all docker images, not just the image used in WPT jobs.
At this point, we were able to use Taskcluster itself to reproduce the issue at scale, creating a task group of identical tasks running the reproduction recipe. The "completed" tasks in that group are the successful reproductions.
Armed with quick, reliable reproduction, we were able to start capturing dumps of the network traffic. From these, we learned that the downloads were failing mid-download (tens of MB into a ~65MB file). We were also able to confirm that the error is, indeed, a TCP RST segment from the peer.
Searches for similar issues around this time found a blog post entitled "Fix a random network Connection Reset issue in Docker/Kubernetes", which matched our issue in many respects. It's a long read, but the summary is that conntrack, which is responsible for maintaining NAT tables in the Linux kernel, sometimes gets mixed up and labels a valid packet as INVALID. The default configuration of iptables forwarding rules is to ignore INVALID packets, meaning that they fall through to the default ACCEPT for the FILTER table. Since the port is not open on the host, the host replies with an RST segment. Docker containers use NAT to translate between the IP of the container and the IP of the host, so this would explain why the issue only occurs in a Docker container.
We were, indeed, seeing INVALID packets as revealed by conntrack -S, but there were some differences from our situation, so we continued investigating.
In particular, in the blog post, the connection errors are seen there in the opposite direction, and involved a local server for which the author had added some explicit firewall rules.
Since we hypothesized that NAT was involved, we captured packet traces both inside the Docker container and on the host interface, and combined the two. The results were pretty interesting! In the dump output below, 74.125.195.136 is dl.google.com, 10.138.0.12 is the host IP, and 172.17.0.2 is the container IP. 10.138.0.12 is a private IP, suggesting that there is an additional layer of NAT going on between the host IP and the Internet, but this was not the issue.
A "normal" data segment looks like
22:26:19.414064 ethertype IPv4 (0x0800), length 26820: 74.125.195.136.https > 10.138.0.12.60790: Flags [.], seq 35556934:35583686, ack 789, win 265, options [nop,nop,TS val 2940395388 ecr 3057320826], length 26752
22:26:19.414076 ethertype IPv4 (0x0800), length 26818: 74.125.195.136.https > 172.17.0.2.60790: Flags [.], seq 35556934:35583686, ack 789, win 265, options [nop,nop,TS val 2940395388 ecr 3057320826], length 26752
here the first line is outside the container and the second line is inside the container; the SNAT translation has rewritten the host IP to the container IP. The sequence numbers give the range of bytes in the segment, as an offset from the initial sequence number, so we are almost 34MB into the download (from a total of about 65MB) at this point.
We began by looking at the end of the connection, when it failed.
A
22:26:19.414064 ethertype IPv4 (0x0800), length 26820: 74.125.195.136.https > 10.138.0.12.60790: Flags [.], seq 35556934:35583686, ack 789, win 265, options [nop,nop,TS val 2940395388 ecr 3057320826], length 26752
22:26:19.414076 ethertype IPv4 (0x0800), length 26818: 74.125.195.136.https > 172.17.0.2.60790: Flags [.], seq 35556934:35583686, ack 789, win 265, options [nop,nop,TS val 2940395388 ecr 3057320826], length 26752
B
22:26:19.414077 ethertype IPv4 (0x0800), length 2884: 74.125.195.136.https > 10.138.0.12.60790: Flags [.], seq 34355910:34358726, ack 789, win 265, options [nop,nop,TS val 2940395383 ecr 3057320821], length 2816
C
22:26:19.414091 ethertype IPv4 (0x0800), length 56: 10.138.0.12.60790 > 74.125.195.136.https: Flags [R], seq 821696165, win 0, length 0
...
X
22:26:19.416605 ethertype IPv4 (0x0800), length 66: 172.17.0.2.60790 > 74.125.195.136.https: Flags [.], ack 35731526, win 1408, options [nop,nop,TS val 3057320829 ecr 2940395388], length 0
22:26:19.416626 ethertype IPv4 (0x0800), length 68: 10.138.0.12.60790 > 74.125.195.136.https: Flags [.], ack 35731526, win 1408, options [nop,nop,TS val 3057320829 ecr 2940395388], length 0
Y
22:26:19.416715 ethertype IPv4 (0x0800), length 56: 74.125.195.136.https > 10.138.0.12.60790: Flags [R], seq 3900322453, win 0, length 0
22:26:19.416735 ethertype IPv4 (0x0800), length 54: 74.125.195.136.https > 172.17.0.2.60790: Flags [R], seq 3900322453, win 0, length 0
Segment (A) is a normal data segment, forwarded to the container.
But (B) has a much lower sequence number, about 1MB earlier in the stream, and it is not forwarded to the docker container.
Notably, (B) is also about 1/10 the size of the normal data segments -- we never figured out why that is the case.
Instead, we see an RST segment (C) sent back to dl.google.com.
This situation repeats a few times: normal segment forwarded, late segment dropped, RST segment sent to peer.
Finally, the docker container sends an ACK segment (X) for the segments it has received so far, and this is answered by an RST segment (Y) from the peer, and that RST segment is forwarded to the container. This final RST segment is reasonable from the peer's perspective: we have already reset its connection, so by the time it gets (X) the connection has been destroyed. But this is the first the container has heard of any trouble on the connection, so it fails with "Connection reset by peer".
So it seems that the low-sequence-number segments are being flagged as INVALID by conntrack and causing it to send RST segments. That's a little surprising -- why is conntrack paying attention to sequence numbers at all? From this article it appears this is a security measure, helping to protect sockets behind the NAT from various attacks on TCP.
The second surprise here is that such late TCP segments are present. Scrolling back through the dump output, there are many such packets -- enough that manually labeling them is infeasible. However, graphing the sequence numbers shows a clear pattern:
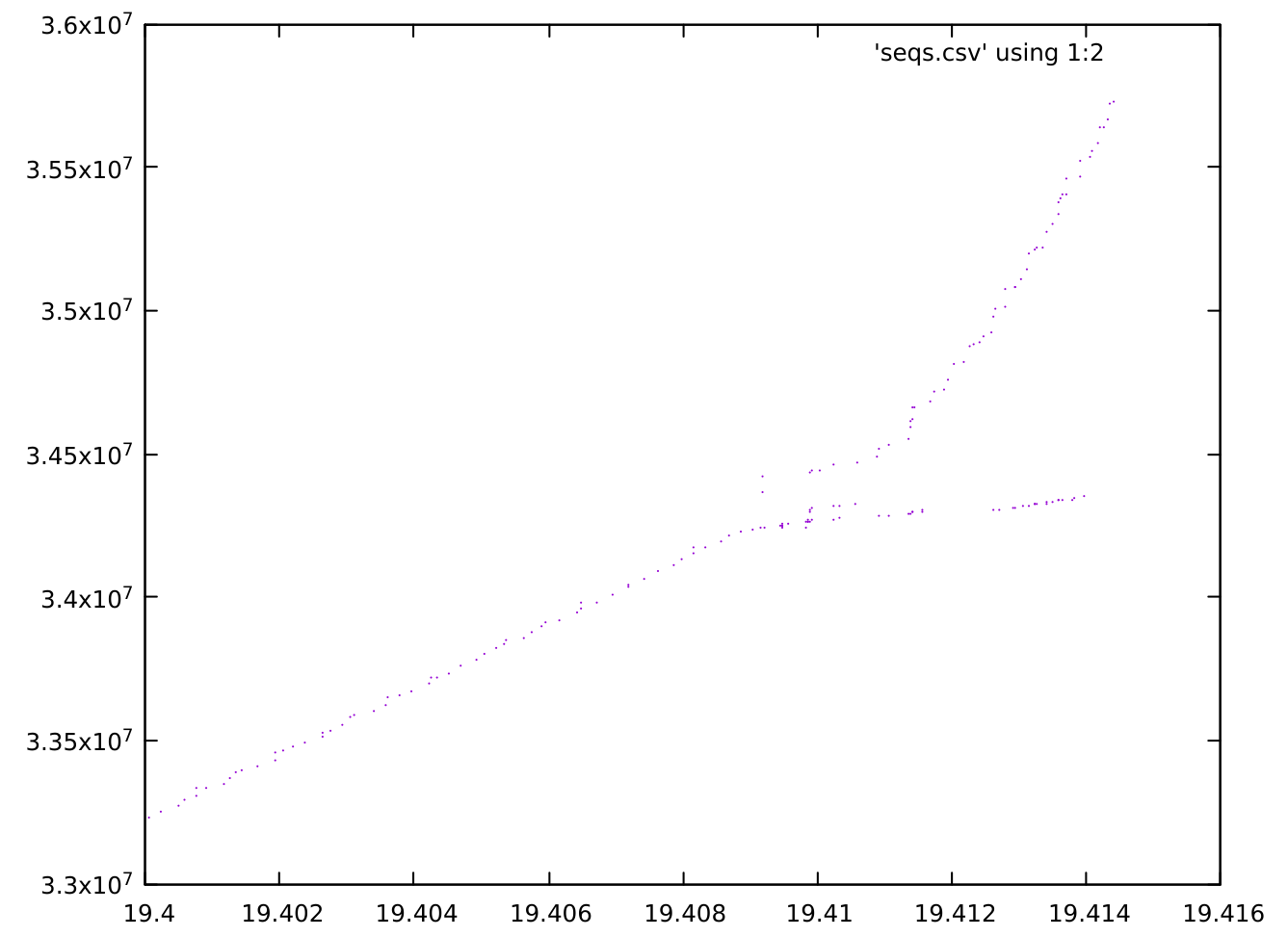
Note that this covers only the last 16ms of the connection (the horizontal axis is in seconds), carrying about 200MB of data (the vertical axis is sequence numbers, indicating bytes). The "fork" in the pattern shows a split between the up-to-date segments, which seem to accelerate, and the delayed segments. The delayed segments are only slightly delayed - 2-3ms. But a spot-check of a few sequence ranges in the dump shows that they had already been retransmitted by the time they were delivered. When such late segments were not dropped by conntrack, the receiver replied to them with what's known as a duplicate ACK, a form of selective ACK that says "I have received that segment, and in fact I've received many segments since then."
Our best guess here is that some network intermediary has added a slight delay to some packets. But since the RTT on this connection is so short, that delay is relatively huge and puts the delayed packets outside of the window where conntrack is willing to accept them. That helps explain why other downloads, from hosts outside of the Google infrastructure, do not see this issue: either they do not traverse the intermediary delaying these packets, or the RTT is long enough that a few ms is not enough to result in packets being marked INVALID.
Resolution
After we posted these results in the issue, our users realized these symptoms looked a lot like a Moby libnetwork bug. We adopted a workaround mentioned there where we use conntrack to drop invalid packets in iptables rather than trigger RSTs
iptables -I INPUT -m conntrack --ctstate INVALID -j DROP
The drawbacks of that approach listed in the bug are acceptable for our uses. After baking a new machine images we tried to reproduce the issue at scale as we had done during the debugging of this issue and were not able to. We updated all of our worker pools to use this image the next day and it seems like we're now in the clear.
Security Implications
As we uncovered this behavior, there was some concern among the team that this represented a security issue. When conntrack marks a packet as INVALID and it is handled on the host, it's possible that the same port on the host is in use, and the packet could be treated as part of that connection. However, TCP identifies connections with a "four-tuple" of source IP and port + destination IP and port. But the tuples cannot match, or the remote end would have been unable to distinguish the connection "through" the NAT from the connection terminating on the host. So there is no issue of confusion between connections here.
However, there is the possibility of a denial of service. If an attacker can guess the four-tuple for an existing connection and forge an INVALID packet matching it, the resulting RST would destroy the connection. This is probably only an issue if the attacker is on the same network as the docker host, as otherwise reverse-path filtering would discard such a forged packet.
At any rate, this issue appears to be fixed in more recent distributions.